LLMs Understand Base64
A fun thing I recently learned about Large Language Models (LLMs) is that they understand base64, a simple encoding of text. Here’s a demonstration: the base64 encoding of What is 2 + 3? is V2hhdCBpcyAyICsgMz8=. Passing that to an LLM, say ChatGPT or Gemini, answers the question perfectly:
 |
And that isn’t just a one-off. It works remarkably well. Here’s another example: taking the string What is the capital of Finland? and converting it to base64 yields V2hhdCBpcyB0aGUgY2FwaXRhbCBvZiBGaW5sYW5kPw==. Again, prompting the LLM with that works just as well as prompting it with the original string:
 |
Like anything with LLMs, the behavior isn’t 100% consistent. Sometimes the models also reply in base64. Sometimes they just decode from base64 and don’t actually answer the question encoded in the message. And sometimes they flat out refuse to respond at all.
Still, LLMs understand base64 surprisingly well. But why is that? Let’s investigate.
How base64 works
Base64 is a simple encoding of strings. The 64 characters [a-zA-Z0-9+/] form the base of the encoding. A base64 string of length 10 can thus represent 64^10 different messages.
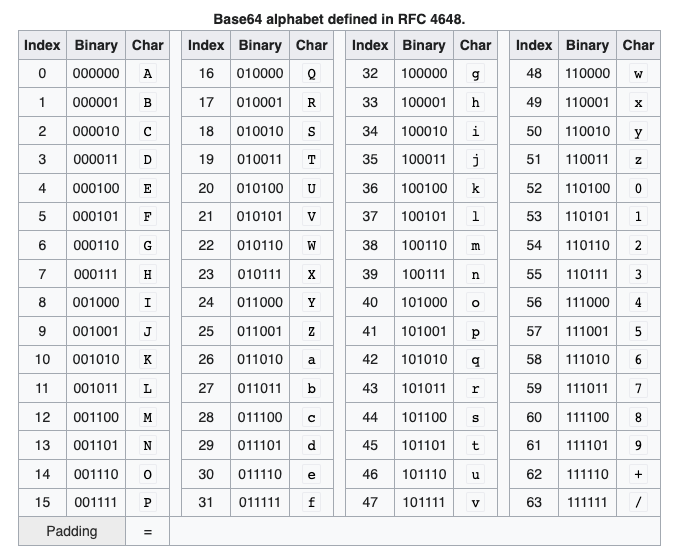 |
To encode a UTF-8 string in base64, you take its binary representation and use the above table to encode it as base64. The = character is used at the end of the base64 representation if there is a need to pad to a certain length. That is why many strings encoded in base64 will end with an equals sign. To decode, you simply take the binary representation and convert from that to your target encoding.
But why do LLMs understand base64? Admittedly, the transformation is rather simple, and the fact that many base64 strings will end with a = makes them easy to detect. However, there is a transformation needed that would not happen naturally during the LLM’s tokenization or embedding steps. Converting three UTF8-encoded characters produces four completely different characters in base64. To convert, there is some work needed that would not happen anyways just because of the way the model is set up.
base64 on the internet
The solution in the puzzle probably lies in the fact that there is plenty of base64 on the internet. Base64 is commonly used in web development to encode things, e.g. images. Hence, there are also a lot of tutorials on the internet on how base64 actually works.
During pre-training, LLMs are commonly trained on massive amounts of data scraped from the internet. The typical task they are trained on is masked token prediction. Of course, if you have to predict masked tokens on a website containing base64, it is rather beneficial to understand how base64 works.
To illustrate this, let’s take the second sentence of this blog post:
The base64 encoding of
What is 2 + 3?isV2hhdCBpcyAyICsgMz8=.
Let’s say we mask it like this:
The base64 encoding of
What is 2 + [MASK]?isV2hhdCBpcyAyICsgMz8=
The LLM is now asked to predict the missing token and trained on whether it got it right or wrong. How can it figure out the missing token? Either it memorizes all instances of base64 on the internet, or it learns how to encode and decode base64. The latter is of course much simpler and more feasible, so that’s what training the model will guide it to.
More concretely, during training, the model will make predictions for masked tokens, such as the one above. If it does not get it right, its weights will be updated to move in a direction where it will be more likely to get the masked token right, hence taking a step towards understanding base64.
Training on the above example of masking thus enforces an understanding of how to decode from base64. Conversely, you could also mask it this way to induce an understanding of how to encode to base64:
The base64 encoding of
What is 2 + 3?is[MASK].
To get the masked token right, the model needs to be able to convert to base64.
Learning and compression
Effectively, learning to encode and decode base64 is a form of compression. It is more economical to learn the rule than to memorize all instances of the rule being applied.
It’s been a longstanding saying that compression is learning, and vice versa. That idea always made some intuitive sense to me – if you want to compress things, you need to understand patterns in the data you are trying to compress. With LLMs, I find it much easier to illustrate that idea though.
Here’s a hypothetical example to this end: let’s say you have a corpus of all 100M+ books written in the entire history of our world. How can you compress that? Many of the books are translated to several other languages. Hence, one way to compress would be to just keep the original copies and then learn how to translate them well into the other languages. It’s a lossy form of compression because you wouldn’t always verbatim reconstruct the phrases actually used in the books. But it’s a form of compression nevertheless. The more books and the more languages you want to compress, the better it works.
LLMs understanding base64 is a bit like that. Instead of memorizing both the decoded and encoded strings, it is much cheaper to learn how base64 works. However, this time, it is not even lossy compression. It is a perfect reconstruction of the original.
But why does the LLM follow instructions?
One question remains though: why do LLMs follow the base64 instruction? A lot of times, they not only decode the message but actively try to answer the question included in the message.
The reason for that behavior is not as obvious to me. My best guess is that LLMs are so tuned to be helpful that it’s just more natural for them to follow the instruction than to just translate it.
Going back to the language translation example: when prompted with an instruction in a different language, LLMs also do their best to follow the instruction. I can e.g. prompt LLMs in French or German, and they will try to answer my questions. They will only translate to English if that’s explicitly what I asked for. Maybe it’s similar with base64; the default behavior taught during instruction tuning is to follow the instruction, not to just convert it to a different encoding.
Conclusion
Concluding the post, LLMs likely understand base64 because it helps them to predict masked tokens on websites that contain base64, of which they are plenty on the internet. This really shows the power of training models to predict masked tokens.
However, the grander thought I have while thinking about this is that it is pretty cool that we’re now at a point in machine learning where models have gotten so good that they surprise us with their abilities. It hasn’t been that long since we’ve had shallow models that were not too difficult to interpret. Over time, models got harder to interpret, but now we’re at a point where models actively surprise us with emergent behavior.